
AIの開発において、精度の高い予測ができる「ランダムフォレスト」は欠かせません。しかし、ランダムフォレストという言葉は知っていても、内容を詳しく知らない人は多いです。
この記事では、ランダムフォレストの概要やメリット・デメリット、具体的な活用事例を紹介します。
ランダムフォレストを上手に活用する基礎知識が身につくため、ぜひ最後までご覧ください。
ランダムフォレスト(Random Forest)とは
ランダムフォレストとは、複数の「決定木」を使用する、精度の高いアンサンブル学習のアルゴリズムです。2001年にアメリカの統計学者であるレオ・ブレイマンにより開発されました。
近年では「ディープラーニング」や「XGBoost」などの機械学習が主力になってきましたが、比較的簡単に実装できるランダムフォレストはいまだに根強い人気があります。
ランダムフォレストの精度が高い理由は、アンサンブル学習にあります。
 あいちゃん
あいちゃんアンサンブル学習により、複数の決定木を組み合わせるため、単一のモデルよりも精度が高くなるのです。
ランダムフォレストでは、アンサンブル学習の中でも「バギング」という手法を用いています。
専門用語が多くなってきたので、単語の意味をわかりやすく解説していきましょう。
決定木とは
ランダムフォレスト(ディシジョンツリー・decision tree)は、複数の決定木を集めて平均値を算出します。
決定木とは、木の幹のような構造でデータを分類していく手法です。決定木はある程度の精度があり、結果の視認性が高いため、機械学習だけでなく統計やマーケティングの分野でも活用されています。

たとえば、外食する人・しない人の細かなデータが与えられていた場合、決定木では以下のように分類していきます。
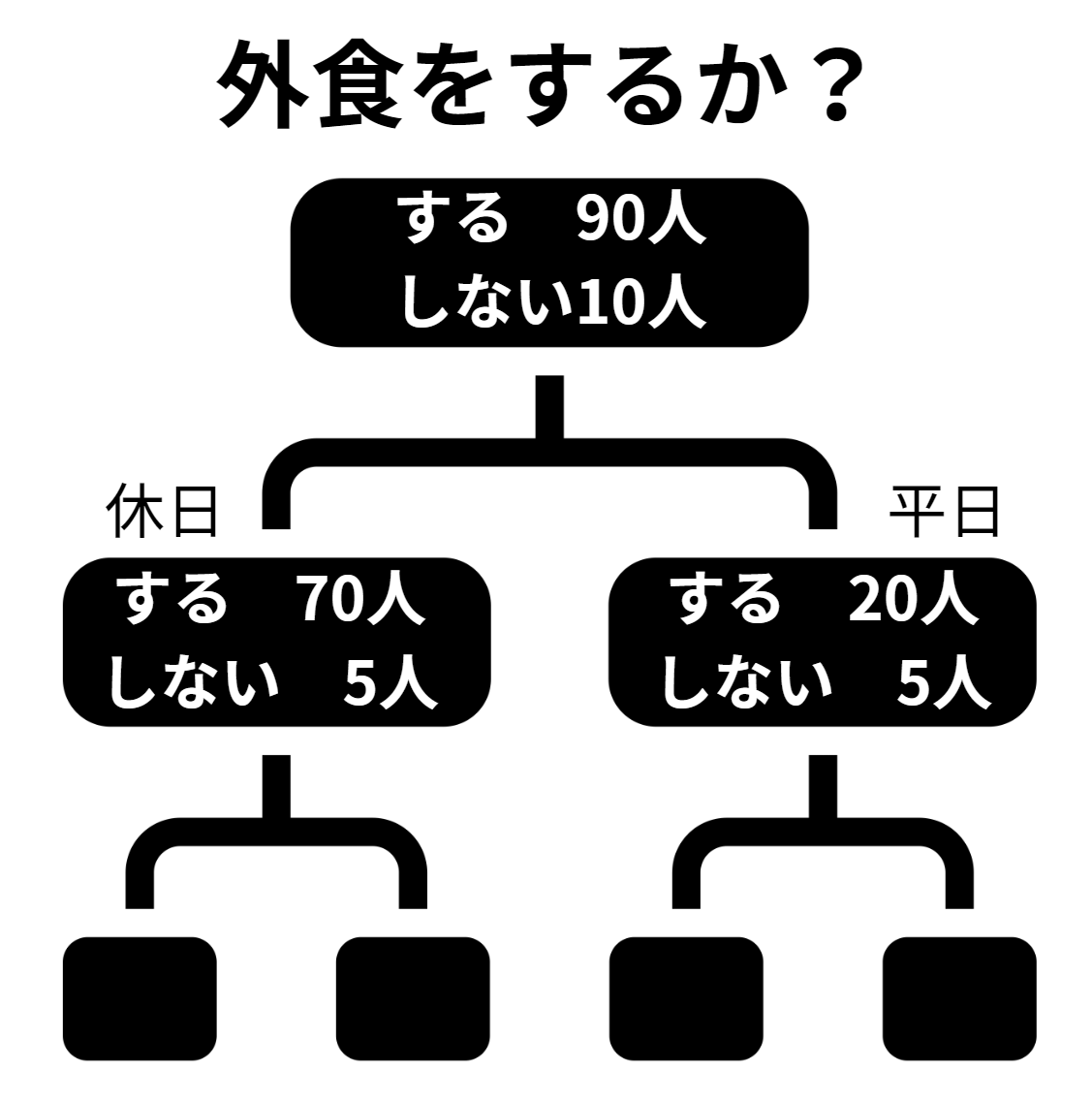
与えられた大量のデータを分析するには、要素ごとに分類すると理解しやすいです。
外食のデータの場合では、まず外食をする人・しない人に分類します。その後、「休日に外食をする人」「平日に外食をする人」に細かく分類していきます。
あいちゃんこのように分類すると、休日や平日などの要素が、消費者の行動にどのような影響を与えているか分析できるのです。
アンサンブル学習とは
ランダムフォレストの核ともいえる「アンサンブル学習」とは、複数のモデルの組み合わせにより、最終的な値の精度が高まる学習方法です。
もともとは音楽用語で、2人以上で演奏することを指す「アンサンブル(emsemble)」が由来となっています。
それほど精度の高くない学習モデルであっても、複数のモデルを融合させれば精度が高くなります。
 あいちゃん
あいちゃん日本のことわざである「三人寄れば文殊の知恵」と同じような考え方です。
たとえば、学習モデルA・B・Cに「〇×問題」を4問出したとします。
それぞれの学習モデルの正解率が75%となった場合に、アンサンブル学習を取り入れると、正解だと予想される答えを導き出すため、正解率は100%となります。
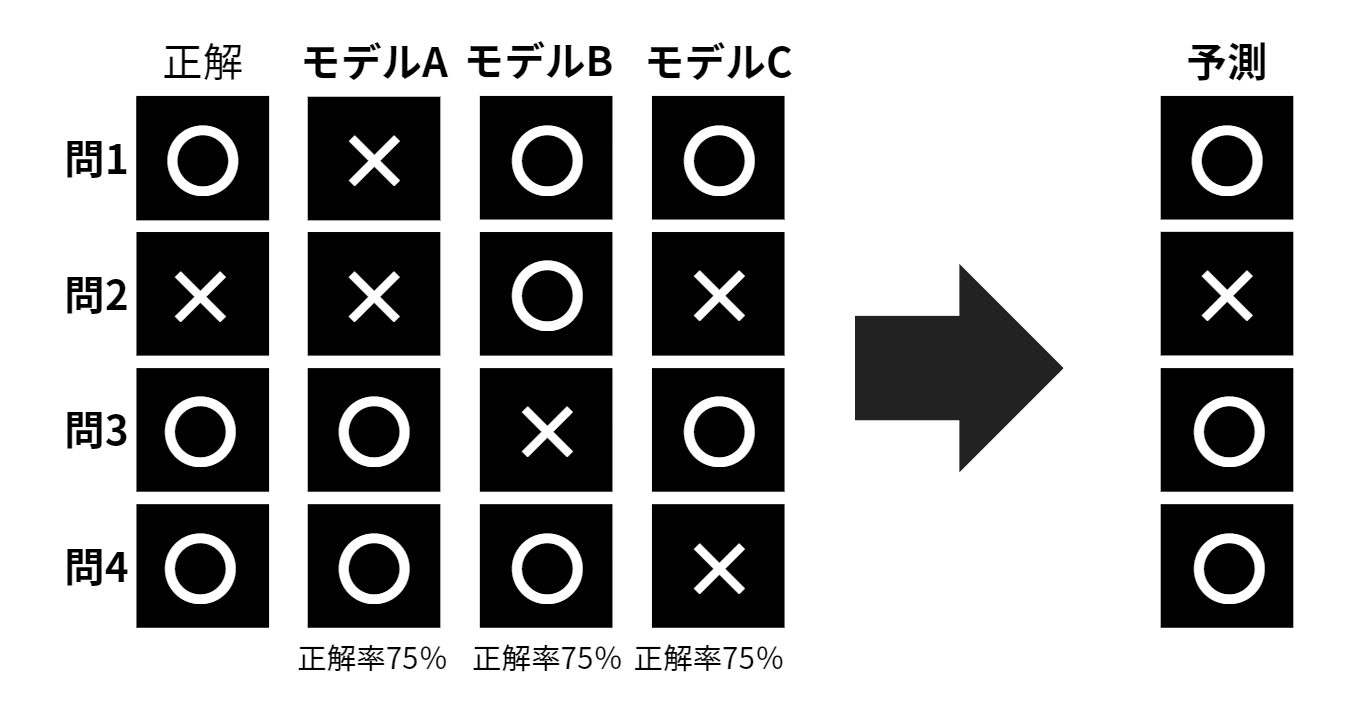
上記の問題のように「分類」であれば、各学習モデルの多数決で決まるのがアンサンブルです。
「回帰」の場合は、各学習モデルの平均で予測値が決まります。
回帰とは、連続する値に対して、次の値を予測することです。回帰を活用すると、過去の購買行動から新商品を何回購入するかを予測できます。
バギングについて
アンサンブル学習にはいくつかの手法がありますが、ランダムフォレストは「バギング」という手法が用いられます。
バギング(Bagging)とは、複数の学習モデルからデータを集め、そのデータをもとに最終的な値を予測する手法です。
あいちゃん難易度が低く、精度が良いため、ランダムフォレストの中でも一般的に活用されています。
ブースティングについて
ブースティングとは、過去のデータの誤差や間違いをもとに、修正を繰り返して精度を向上させる手法です。
ブースティングはバギングよりも精度が高いとされていますが、過学習になる可能性があります。
過学習とは、データを学習し過ぎて、予測が上手にできなくなる状態です。ブースティングで過学習が発生すると、汎用性がなくなるので注意が必要です。
あいちゃんまた、ブースティングは並列の処理ができないため、計算量が膨大になり時間がかかる特徴もあります。
ランダムフォレストの仕組み
ここまでに解説したように、ランダムフォレストは以下の2つが核となっています。
- 決定木
- アンサンブル学習
木の幹のような構造でデータを分析して、かつ複数の学習モデルを組み合わせることにより精度の高い結果を導き出す仕組みです。
ランダムフォレストでは、アンサンブル学習を以下の2つの手法を活用しています。
- バギング:複数のモデルを並列に学習して、平均で予測をおこなう
- ブースティング:モデルを着列に学習して、間違いを修正していく
これらの分析方法や手法の組み合わせが、ランダムフォレストの仕組みです。
あいちゃんアルゴリズムは以下のようになります。
- 元データからブートストラップでn個のグループを作成する
- n個のグループをそれぞれ決定木で学習する
- 学習結果から多数決もしくは平均により予測結果を導き出す
ランダムフォレストの何がすごい?
ランダムフォレストが優れている点は、以下のように複数あります。
- アンサンブル学習により高い精度を実現する
- バギングとブースティングにより「分類」と「回帰」の両方に優れている
- 決定木を基本としていて視認性に優れている
- ハイパーパラメータのチューニングが簡単
- ブートストラップにより過学習を抑制できる
決定木とアンサンブル学習も組み合わせて、初心者でも精度良く、理解しやすいことがランダムフォレストの利点だといえるでしょう。
あいちゃん実際に、機械学習を初めて学ぶ人は、ランダムフォレストから始めるケースが多いです。
ランダムフォレストの欠点
ランダムフォレストは優れている点が多くありますが、デメリットもあります。
デメリットの一つとしてよく挙げられるのは、過学習が発生する点です。ランダムフォレストは、ブートストラップにより過学習の発生を抑えられますが、それでも完全に無くすことはできません。
過学習が発生すると、訓練データとの適合し過ぎて、汎用性がなくなってしまいます。
過学習を抑制するには、ハイパーパラメータの調整が重要です。ハイパーパラメータとは、機械学習を始める際に、事前に設定するパラメータです。ハイパーパラメータで設定できる代表的な値は、以下の通りです。
- 学習率
- 闘値
- エポック数
- パッチサイズ
- 層の数
ハイパーパラメータを調整して、葉数や深さをデータサイズに合わせて小さくしておけば過学習を抑えられます。
あいちゃんまた、もともとのデータから不要な情報や項目を削除することも重要です。
【誰でも簡単】pythonでランダムフォレストを実装
ランダムフォレストは、Pythonの機械学習ライブラリ「Scikit-learn」を使うと実装できます。
Scikit-learnとは、オープンソースの機械学習ライブラリです。分類や回帰などのアルゴリズムを搭載していて、ランダムフォレストには欠かせません。使用方法もシンプルなので、初心者でも、難なく扱えるでしょう。
Scikit-learnは、Pythonのパッケージ管理ツールで、以下のコマンドを入力するとインストールできます。
pip install scikit-learn
Scikit-learnには、さまざまなサンプルデータセットが付いています。たとえば、ライブラリの中から、花の「あやめ」のデータをインポートするには、以下のコマンドを入力してください。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
データセットをインポートしたら、以下のコマンドでデータを読み込みます。
iris_list = load_iris()
続いて、学習用データとテスト用データに分割します。データの分割により、学習モデルの訓練と評価を適切におこなえます。
データの分割は、以下のコマンドを入力してください。
x_train, x_test, t_train, t_test = train_test_split(
iris_list.data, iris_list.target, test_size=0.3, random_state=0)
print(len(x_train))# 105
print(len(x_test))# 45
上記のコマンドを入力すると、データが7:3に分割されます。
最後にランダムフォレストを構築して、データを与えたら準備完了です。
model = RandomForestClassifier()
model.fit(x_train, t_train)
ランダムフォレストの使用例
ランダムフォレストは、医療業界や金融業界・マーケティングなど、幅広い目的で使用されています。
ここでは、ランダムフォレストの具体的な使用例を紹介します。
1.医療業界
医療業界ではランダムフォレストを使用して、患者の死亡率や在室日数を予測しています。
空き病床を予測できれば、より効率的に患者の受け入れができるためです。
あいちゃん実際にカルテデータを利用して、ICUに入院した患者の在室日数を分析したところ、高い精度で予測できました。
また、患者の退院日を予測すれば、医療従事者の負担を軽減できるだけでなく、患者自身のQOL向上にも繋がるでしょう。
あいちゃんランダムフォレストは、新型コロナウイルス感染症でも活躍しました。
ICUに入院した新型コロナウイルス感染症の患者の診察情報から、人工呼吸器やECMOが必要になる人を予測して、医療機器の整備をする重要な情報となったのです。
このようにランダムフォレストは、医療業界を陰から支えています。
2.マーケティング
小売業界では顧客の行動を分析するためのマーケティングに、ランダムフォレストが使用されています。
多くのケースで、顧客の「店内滞在時間」と「客単価」に相関性があるためです。
たとえば、店内に30分以上滞在した顧客は客単価が高くなる傾向にあると分析できれば、力を入れるべき顧客を判断できます。
あいちゃんまた、店員の接客時間と客単価の関係性も分析できれば、さらに接客を効率化できるでしょう。
その他にも、顧客には以下のような属性があります。
- 来店時の人数(一人・カップル・家族など)
- 年齢層
- 来店した曜日や時間
- 来店日の天気
上記の項目をランダムフォレストで分析すれば、これまでに分からなかった、顧客の購買行動が判明するでしょう。
3.金融業界
金融業界では、ランダムフォレストをESG投資の信用格付けに利用しています。
あいちゃんESG投資とは、以下の3つの要素から構成されています。
- 環境(Environment)
- 社会(Social)
- ガバナンス(Governance)
ESGは上記の3つの単語の頭文字を取った言葉で、機関投資家が企業に出資する際の大きな指標です。
ESGは、財務諸表のように数字だけで判断できないため、信用格付けが難しいとされていました。しかし、ランダムフォレストの活用により、信用格付けの予測精度が高まりました。
まとめ
ランダムフォレストとは、複数の決定木を使用する、精度の高いアンサンブル学習のアルゴリズムです。
決定木は、木の幹のような構造でデータを分析する手法です。複数のデータから分析・予測するアンサンブル学習と組み合わせると、精度の高い予測が可能になります。
また、分析と回帰の両方に優れていて、ハイパーパラメータの調整が容易なこともメリットの一つです。
ただし、過学習になる可能性があるため、注意が必要です。過学習を予防するには、元データから不要な部分を事前に削除しておきましょう。また、ハイパーパラメータを調整して、葉数や深さを設定することも重要です。
ランダムフォレストは、医療業界や金融業界・マーケティングなど幅広い分野に使用されています。初心者でも扱いやすいため、今後もさまざまな業界で活用されるでしょう。

コメント